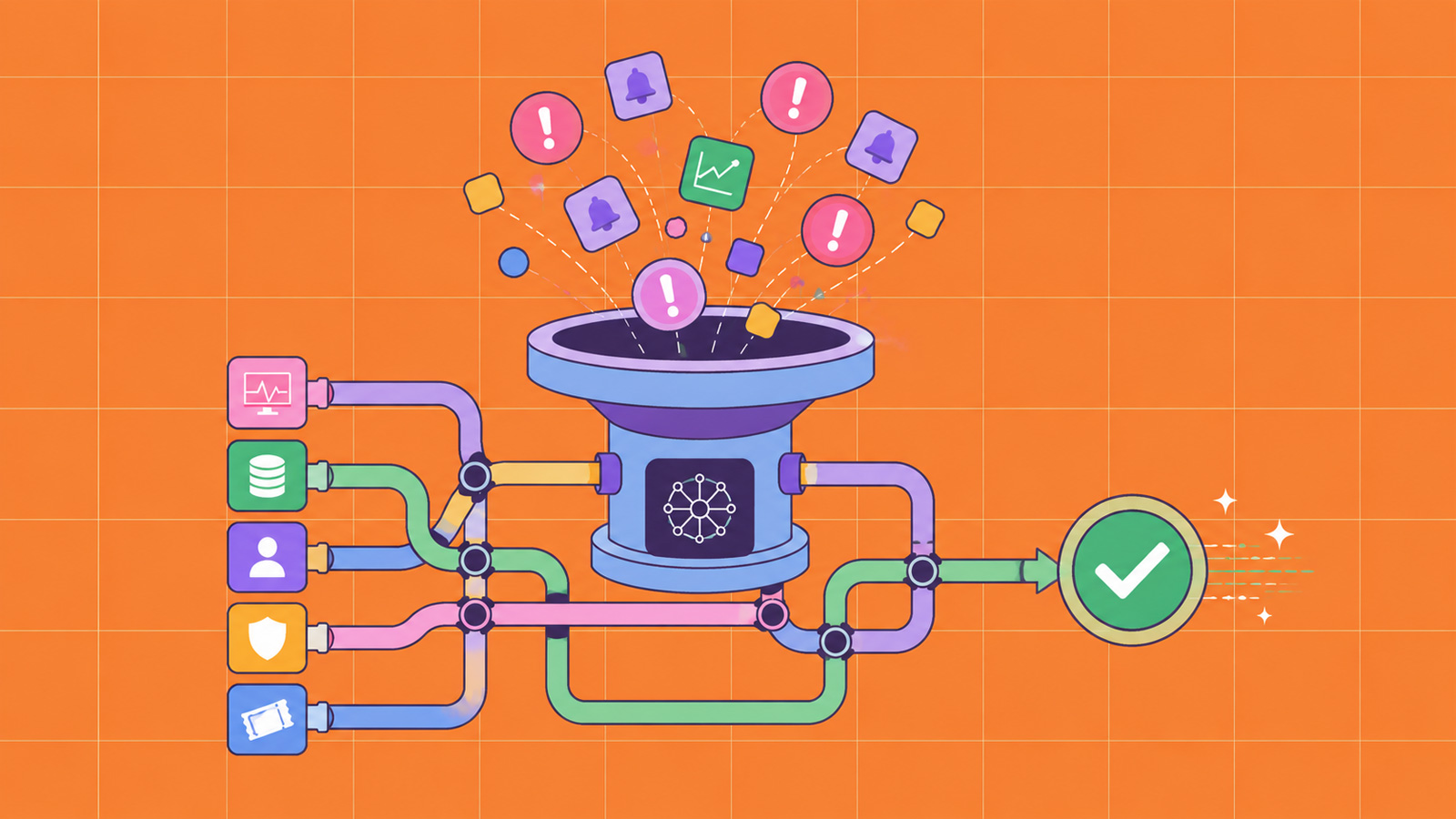
The sheer volume of alerts hitting IT departments isn’t just noise; it’s a financial and operational liability waiting to happen.
On June 2, 2026, BleepingComputer is hosting a webinar, “From alert to resolution: Fixing the gaps in network incident response.” Edgar Ortiz, a Solutions Engineering Leader and Computer Scientist at Tines, will explore why high-pressure situations routinely cripple incident response workflows. It’s not about getting the alert; it’s about what happens next. And that’s precisely where the cracks appear.
Organizations are still relying on manual triage, investigation, and routing processes. This isn’t just inefficient; it’s a direct pipeline to increased downtime and service disruptions. Think about it: a critical network event unfolds, and instead of a swift, automated response, analysts are left clicking between a dozen different dashboards, trying to piece together a narrative that’s already costing the business dearly. This is the operational friction that automation, specifically AI-assisted workflows, promises to eliminate.
Tines itself positions its platform as a builder of intelligent workflows, connecting disparate systems and automating the repetitive, time-consuming tasks that bog down IT teams. The promise is clear: reduce manual overhead, close the gaps between alerting, triage, analysis, routing, and the eventual resolution.
Manual Workflows Are Draining Resources
Network incidents are, by their very nature, chaotic. They demand a rapid synthesis of information from various sources – network logs, identity services, ticketing platforms, security tools – to even begin understanding the scope. Then comes the human element: manually determining ownership, prioritizing the incident based on often incomplete data, and coordinating action across multiple teams, often via email or chat threads that quickly become unmanageable.
This webinar aims to dissect exactly where these workflows falter. It’s a critical look at the friction points that turn a potentially minor incident into a full-blown crisis.
What’s on the Agenda?
- The typical lifecycle of a network incident, from that initial blip on the radar to the painful service impact.
- Pinpointing the breakdown points in triage, enrichment, and routing – those moments where manual effort becomes a bottleneck.
- Techniques for automatically pulling in network, identity, and threat context to enrich alerts on the fly.
- Strategies for prioritizing and routing incidents without a human having to lift a finger – a bold but necessary claim.
- The crucial shift from fragmented, ad-hoc responses to a truly coordinated, system-wide resolution.
It’s easy for vendors to talk about automation and AI. The real challenge lies in demonstrating tangible improvements in operational efficiency during moments of peak stress. This webinar, by focusing on the bottlenecks, suggests a pragmatic approach that’s less about the hype and more about the practical realities of IT operations.
My unique insight here? This isn’t just about faster incident response; it’s about reclaiming valuable engineering time. The hours spent on manual, repetitive tasks during incidents could be far better allocated to proactive security measures, system improvements, or strategic development. The market dynamics clearly show a growing gap between the sophistication of threats and the manual capacity of IT teams. Automation, when implemented correctly, is the only viable bridge across that chasm. The persistent reliance on manual processes in 2026, when AI is demonstrably capable of handling these tasks, is a strategic failure for many organizations.
As alert volumes continue to grow, many organizations still rely on manual triage, investigation, and routing processes to respond to network incidents. This creates operational bottlenecks that can slow response times and increase the risk of outages and service disruptions.
This isn’t just an inconvenience; it’s a direct threat to business continuity and profitability. The webinar’s focus on fixing these gaps is not merely an operational tweak; it’s a fundamental necessity for resilient IT infrastructure.
Why Does This Matter for IT Leaders?
For IT leaders, the stakes are immense. The cost of downtime is astronomical, often measured in millions of dollars per hour for larger enterprises. Beyond direct financial losses, there’s the erosion of customer trust, reputational damage, and potential regulatory penalties. The webinar’s emphasis on reducing manual overhead and closing operational gaps directly addresses these high-cost areas.
By attending, leaders can gain actionable insights into how to implement AI-assisted workflows and automation that don’t just promise efficiency but deliver it. This means less time scrambling during crises and more time planning for strategic growth and security posture improvement. It’s about building a more resilient, responsive, and ultimately, more profitable IT operation.
🧬 Related Insights
- Read more: Cloud Breach: Storm-2949’s Identity Hack Spans Entire Azure Estate
- Read more: Claude Mythos Preview: Why Frontier AI Demands Endpoint Armor from CrowdStrike
Frequently Asked Questions
What are the main bottlenecks in network incident response? Manual processes for alert triage, investigation, context enrichment, prioritization, and cross-team coordination are the primary bottlenecks.
Can AI really fix incident response delays? AI-assisted workflows and automation can significantly reduce delays by automating repetitive tasks, providing faster context, and streamlining routing, allowing human analysts to focus on complex decision-making.
What systems does Tines connect to? Tines connects to a wide range of systems through integrations and APIs, enabling the automation of workflows across disparate IT and security tools.




